It's done: Rules 2 is out!
Finally, slightly more than two years after I started the initial development I'm happy to announce the release of Rules 2.0 for Drupal 7!
 You might note, that data selectors like
You might note, that data selectors like 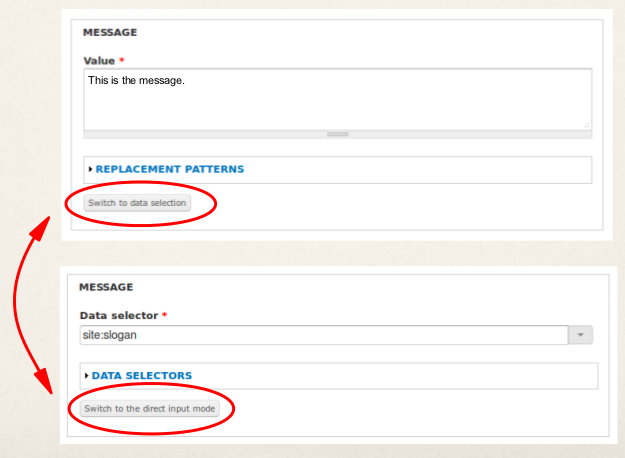
 Furthermore, one can access individual list items directly using the data selector - just use
Furthermore, one can access individual list items directly using the data selector - just use 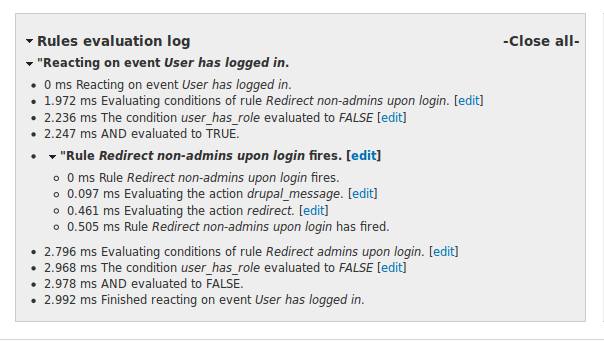
So what's new compared to Rules 1.x?
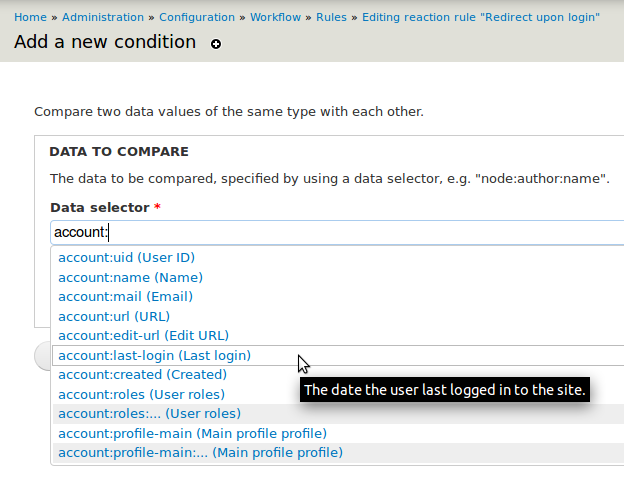
While the fundamental concepts of "Event-Condition-Action rules" and parametrized actions remain, Rules 2.x is a complete re-write - quite some things changed. Now, it's building upon the Entity API module to fully leverage the power of entities and fields in Drupal 7. Change a taxonomy term? - No problem. Moreover that, Rules 2 now allows you to just select any entity property or field via it's so called "data selection" widget:Data selection
The Rules data selection widget shows all suiting data properties when configuring an action or condition argument. Let's consider, you configure an action to send a mail - by using the data selectorcomment:node:author:mail you can easily send mail to the comment's node's author. For that the data selection auto-complete helps you finding suiting data selector:
You might note, that data selectors like node:title look like token replacements. But as actions need more than just textual data, the data selector gives them back the raw data, e.g. full entity objects or whatever fits depending on the data type. Thus, data selectors are not implement via token replacements, but via the entity.module's Entity property info system. Still, the Entity Tokens module (comes with Entity API) makes sure there are token replacements available for all the data selectors too.
The very same way one can naturally access fields too - e.g. node:field-tags gets you all the tags of your article node. However as only articles have tags, for that to work Rules needs to know that the variable node is an article first. Thus, make sure you've used the "Content is of type" or the "Data comparison" condition to check it's an article. Analogously, if you have an "entity" data item you can use the Entity is of type condition to make sure it's a node and access node-specific properties afterwards!
Read more about data selection in the drupal.org handbooks.
Switching parameter input modes
Related, Rules 2 allows you to switch the input modes while configuring the argument for an action parameter. Consider, you have an action that works with a vocabulary. Usually people might select the vocabulary to work with from the list of available vocabularies, but in some circumstances one wants the action to use the vocabulary of a specific taxonomy term. This is, where switching parameter input modes comes into play as it allows you to switch from fixed input mode (= configuring a specific vocabulary) to the data selection input mode - so you could just configureterm:vocabulary as an argument by using the data selection widget.
Rules 2 provides small buttons below each parameter's configuration form which allow you to switch the input mode:
Components
Components are standalone Rules configurations that can be re-used from your reaction rules or from code. In Rules 1.x there are already "rule sets" available as "components" - but with Rules 2.x there are multiple component types: Rule Sets, Actions Sets, Rules, "AND Conditions Sets" and "OR condition sets". Rule sets come with maximum flexibility, but if the extra layer of having multiple rules is unnecessary for your use case, you can go with the simpler action set or a single "rule" component now! Next, the conditions sets make it possible to define re-usable condition components. Components work upon a set of pre-defined variables (e.g. a node), just as for Rules 1.x. However with Rules 2.x it's now possible to provide new variables back to the caller, too. Read more about components in the drupal.org handbooks.Loops and lists
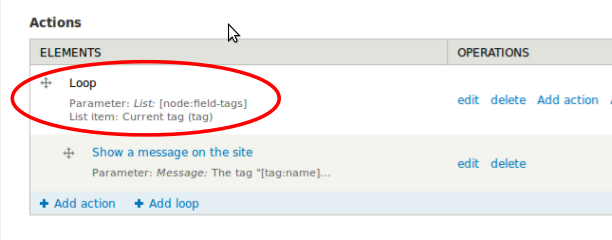
Rules 2 is finally able to properly deal with loops and lists! That means you can now access all your fields with multiple items, e.g. the tags of an article node. So you can easily loop over the list of tags and apply an action to each tag. That's also very handy in combination with node-reference or user-reference fields. Send a notification mail to all the referenced users? No problem.
Furthermore, one can access individual list items directly using the data selector - just use node:field-tags:0:name to access the first tag. If you do so, you might want to check whether a tag has been specified by using the "Data value is empty" condition though.
Read more about loops in the drupal.org handbooks.
Improved debug log
Fortunately, there has been another Rules related Google Summer of Code project this year. Sebastian Gilits worked on improving the rules debug log as part of his project! Now, the debug log makes use of some Javascript and appears all collapsed by default, so it's much easier to get which events have been triggered and which rules have fired in the first place. Also, we've included edit links so you can easily jump from the debug log to the Rules UI in order to fix up a miss-configured rule. Unfortunately, the data of the city of Linz required some custom massaging in order to get proper geo coordinates from the project they used. Thus, we were not able to create easy to use feeds configurations for Linz as we've done for Vienna. Maybe the city of Linz improves that in the future...
Unfortunately, the data of the city of Linz required some custom massaging in order to get proper geo coordinates from the project they used. Thus, we were not able to create easy to use feeds configurations for Linz as we've done for Vienna. Maybe the city of Linz improves that in the future...
