drupal
Introducing fluxkraft - web automation simplified with the power of Rules!
You might have heard some rumors about a tool called "fluxkraft": something like ifttt.com, but with Rules? Or what? Indeed, fluxkraft is one of our latest drunomics lab projects funded by netidee - a Austrian grant for powerful - and open - innovations, and yes - fluxkraft will be a tool for rule-based web automation, built as an open platform on top of Rules and Drupal! So, finally here are some first details on it:
So the idea is to build an easy to use Drupal distribution that allows you to automate various web-based tools like twitter, facebook and dropbox. Yes, you can do that already with services like ifttt.com, but fluxkraft will be an open platform, open-source and free for everyone to use and extend. That way, you can install it on your own servers and keep all the keys to your valuable data secured - and most importantly - under your control!
Then, as it's open source and will come with an API for adding connectors to new services you can simply integrate it with any service you want. So while the tool will provide some essential integrations for services like twitter and facebook from the start, the hope is that community will chime in and provide connectors to a variety of different online services.
Rules?
So how does that tie into Rules? Well, Rules already provides a solid technical base, but we'll add an API for easy-integration with external services to it - so we've got the kraft. But for the flux to gain enough strength, we'll build a new UI that makes it super-simple to create, mix, and share the rules that connect the various services together. So yes - we'll build a new Rules UI! Initially, it will be built separately and power fluxkraft, but if everything works out we'll see a new Rules UI pretty soon!
All fine, Doc? So what's the time(line)? We've mostly finished some initial wireframes, so expect a first shout for feedback on the the new UI at the Rules g.d.o. group soon! Then, the fluxkraft team will be working eagerly on the project such that - maybe - we might have a first preview release out for Drupalcon Portland in May. Howsoever, we'd love to share our learnings and show how we are reloading the Rules UX with fluxkraft, so I've proposed session!
Finally, so who's in the boat? Well, it's me "fago" who will be leading the project during the next months - in fact I'll dedicate most of my time to it. But, fortunately I've got some help of Christian Ziegler aka criz (Strategy, Community Management), Sebastien Siemssen aka fubhy (Development) and Nico Grienauer (Design, Inspirator).
If you are interested, follow @fluxkraft on twitter and provide feedback in a short comment below!
Semantic content enhancements with Drupal, Apache Stanbol and VIE.js
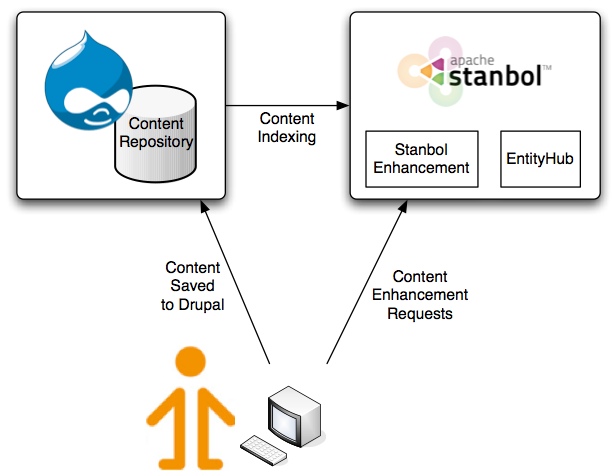
As previously announced on the IKS blog I’ve been recently working together with Stéphane Corlosquet on integrating the tools provided by the IKS project to do semantic content enhancements in Drupal as part of the IKS early adopter program.
The Interactive Knowledge Stack (IKS) project is an open source community which got funded by the EU to build an open and flexible technology platform for semantically enhanced Content Management Systems. Thanks to IKS, open source projects like Apache Stanbol, VIE.js or Create.js got started. While VIE.js and Create.js are already on their way to Drupal 8 via the Spark initiative, our focus was on integrating Apache Stanbol with Drupal 7. In short, Apache Stanbol is a java web application that leverages tools like Apache Solr, Apache Tika or Apache OpenNLP to provide a set of reusable components for semantic content management via RESTful web services. On the front-end side, VIE.js (“Vienna IKS Editables”) is the JavaScript library for implementing decoupled Content Management Systems and semantic interaction in web applications.
For leveraging Apache Stanbol with Drupal we send Drupal’s data over to Apache Stanbol’s EntityHub component for indexing, such that it is available to Apache Stanbol’s content enhancer. That means, we can use VIE widgets like annotate.js to send pieces of text over to Apache Stanbol for auto-linking content items indexed to Stanbol, which by default includes DBpedia entities, but could be easily extended by any source providing data in RDF. Next, the VIE autocomplete widget allows for easy tagging based upon entities indexed with Apache Stanbol - regardless of whether they come from DBPedia or from one of the Drupal sites your organization runs!
There must be Rules at the Drupalcon Munich
As there must be Rules at the Drupalcon Munich as well, I've had a Rules session together with Richard Jones from i-KOS.
Head over to the session page for a summary and find the slides attached attached to this post as well. Moreover, you can find all the screencasts we've used during the presentation here as well. It's a real Drupal commerce site we've been using in the session to show how Rules can be used to solve real life problems.
1 - No VAT for certain products
2 - Discounts for products that are not belts or bags
and then to make it work the same way years ahead3 - Subscribe to back in stock notifications via Flag module.
4 - Notify me when something needs review with Workbench moderation
5 - Execute Rules components from Views Bulk Operations
6 - Let's do promitions, but only on Monday please!
7. Message users if they abandoned their carts
8. Log user communication with the Message module
Going freelance
Some weeks ago I decided to go for something new and to start freelancing. Anyway, I'll keep up the good relationship with epiqo, but starting from December I'm going to work on a freelance basis and look out for other exciting possibilities and projects. Of course I keep maintaining my beloved Drupal modules. Moreover if everything goes well, I hope to be able to reserve more time for community work that way and/or to find new sponsors for exciting developments.
It's done: Rules 2 is out!
Finally, slightly more than two years after I started the initial development I'm happy to announce the release of Rules 2.0 for Drupal 7!
 You might note, that data selectors like
You might note, that data selectors like 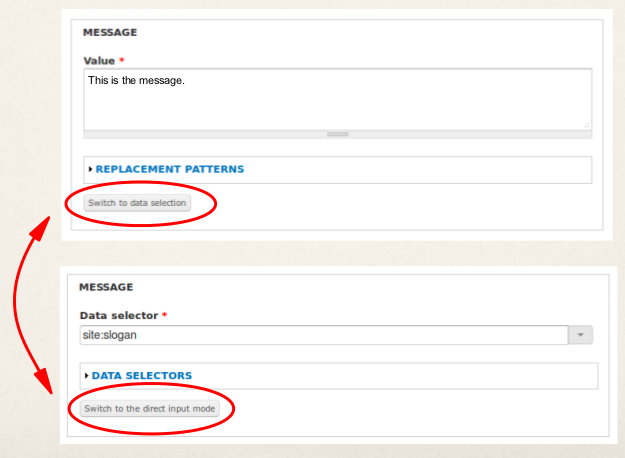
 Furthermore, one can access individual list items directly using the data selector - just use
Furthermore, one can access individual list items directly using the data selector - just use 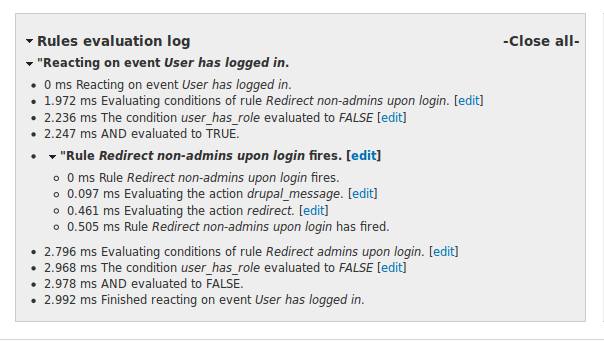
So what's new compared to Rules 1.x?
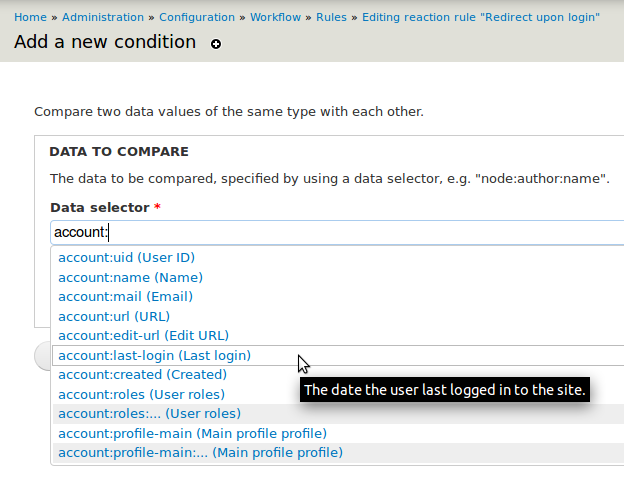
While the fundamental concepts of "Event-Condition-Action rules" and parametrized actions remain, Rules 2.x is a complete re-write - quite some things changed. Now, it's building upon the Entity API module to fully leverage the power of entities and fields in Drupal 7. Change a taxonomy term? - No problem. Moreover that, Rules 2 now allows you to just select any entity property or field via it's so called "data selection" widget:Data selection
The Rules data selection widget shows all suiting data properties when configuring an action or condition argument. Let's consider, you configure an action to send a mail - by using the data selectorcomment:node:author:mail you can easily send mail to the comment's node's author. For that the data selection auto-complete helps you finding suiting data selector:
You might note, that data selectors like node:title look like token replacements. But as actions need more than just textual data, the data selector gives them back the raw data, e.g. full entity objects or whatever fits depending on the data type. Thus, data selectors are not implement via token replacements, but via the entity.module's Entity property info system. Still, the Entity Tokens module (comes with Entity API) makes sure there are token replacements available for all the data selectors too.
The very same way one can naturally access fields too - e.g. node:field-tags gets you all the tags of your article node. However as only articles have tags, for that to work Rules needs to know that the variable node is an article first. Thus, make sure you've used the "Content is of type" or the "Data comparison" condition to check it's an article. Analogously, if you have an "entity" data item you can use the Entity is of type condition to make sure it's a node and access node-specific properties afterwards!
Read more about data selection in the drupal.org handbooks.
Switching parameter input modes
Related, Rules 2 allows you to switch the input modes while configuring the argument for an action parameter. Consider, you have an action that works with a vocabulary. Usually people might select the vocabulary to work with from the list of available vocabularies, but in some circumstances one wants the action to use the vocabulary of a specific taxonomy term. This is, where switching parameter input modes comes into play as it allows you to switch from fixed input mode (= configuring a specific vocabulary) to the data selection input mode - so you could just configureterm:vocabulary as an argument by using the data selection widget.
Rules 2 provides small buttons below each parameter's configuration form which allow you to switch the input mode:
Components
Components are standalone Rules configurations that can be re-used from your reaction rules or from code. In Rules 1.x there are already "rule sets" available as "components" - but with Rules 2.x there are multiple component types: Rule Sets, Actions Sets, Rules, "AND Conditions Sets" and "OR condition sets". Rule sets come with maximum flexibility, but if the extra layer of having multiple rules is unnecessary for your use case, you can go with the simpler action set or a single "rule" component now! Next, the conditions sets make it possible to define re-usable condition components. Components work upon a set of pre-defined variables (e.g. a node), just as for Rules 1.x. However with Rules 2.x it's now possible to provide new variables back to the caller, too. Read more about components in the drupal.org handbooks.Loops and lists
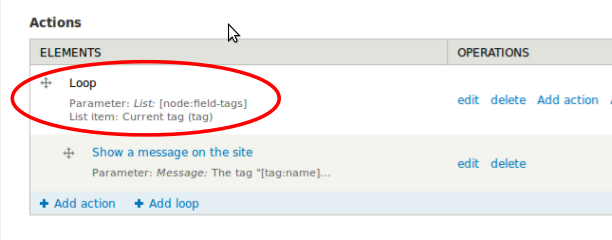
Rules 2 is finally able to properly deal with loops and lists! That means you can now access all your fields with multiple items, e.g. the tags of an article node. So you can easily loop over the list of tags and apply an action to each tag. That's also very handy in combination with node-reference or user-reference fields. Send a notification mail to all the referenced users? No problem.
Furthermore, one can access individual list items directly using the data selector - just use node:field-tags:0:name to access the first tag. If you do so, you might want to check whether a tag has been specified by using the "Data value is empty" condition though.
Read more about loops in the drupal.org handbooks.
Improved debug log
Fortunately, there has been another Rules related Google Summer of Code project this year. Sebastian Gilits worked on improving the rules debug log as part of his project! Now, the debug log makes use of some Javascript and appears all collapsed by default, so it's much easier to get which events have been triggered and which rules have fired in the first place. Also, we've included edit links so you can easily jump from the debug log to the Rules UI in order to fix up a miss-configured rule.Publishing Linked Open Data of Austria at the Vienna Create Camp 11
The last weekend I attended the Vienna Create camp 11, a great event for collaboratively creating applications related to open data and accessibility.
6 members of Drupal Austria formed a team to make use of open data published by the cities of Vienna and Linz. Unfortunately, it turned out that the data is published in various different data structures and formats, so re-using the data in an efficient manner is hard. It's nice to see that the city of Linz is using CKAN to publish the data, so there is some basic information about the data sources (format, url, ..) available. However, still each data set is published using different data structures, so making use of a data source requires writing or configuring a specific adapter.
So, we've started "drupalizing" the data by using feed importers, whereby we've configured one content type and feeds importer per data source. Fortunately, once the data is in Drupal we can use it with all of Drupal's tools. So publishing the data as Linked Open Data is as easy as enabling the "rdf" module of Drupal and providing some meaningful mappings. For that, we've made use of Schema.org vocabularies as far as possible.
Now, all imported data items are available via RDFa, RDF, JSON or XML. But most convenient is probably the Sparql endpoint, which enables one to directly query the published datasets. So finally, we have real Linked Open Data of Austria - yeah! Then, we've made use of Openlayers with some nice base layers from the TileStream powered kartenwerkstatt.at to create nice looking maps - check out the demonstration site.
Next, we've published our open data features at drupal.org, so everyone can easily make use of our work and quickly use all that data by using Drupal. See http://drupal.org/project/odv.
 Unfortunately, the data of the city of Linz required some custom massaging in order to get proper geo coordinates from the project they used. Thus, we were not able to create easy to use feeds configurations for Linz as we've done for Vienna. Maybe the city of Linz improves that in the future...
Unfortunately, the data of the city of Linz required some custom massaging in order to get proper geo coordinates from the project they used. Thus, we were not able to create easy to use feeds configurations for Linz as we've done for Vienna. Maybe the city of Linz improves that in the future...
Unfortunately, the data of the city of Linz required some custom massaging in order to get proper geo coordinates from the project they used. Thus, we were not able to create easy to use feeds configurations for Linz as we've done for Vienna. Maybe the city of Linz improves that in the future...
Speeding-up Drupal test-runs on Ubuntu 11.04
Using a ramdisk for MySQL helps *a lot* to speed up simpletests in Drupal, as well as disabling innodb as described on the according d.o. docu page.
While the documentation provides an init.d script, Ubuntu 11.04 comes with an upstart script for MySQL. So I modified the instructions and come up with the following in order to put MySQL on a ramdisk on ubuntu 11.04 (and later):
Nginx clean-URLs for Drupal installed in various sub-directories
klausi has already posted a nice, actually working nginx configuration for Drupal on his blog. This configuration is intended for Drupal installations installed on separate (sub)domains. However, recently I came up with the need of having multiple Drupal installations in sub-directories for my development environment. To achieve that I've created the following location directive:
That way, you can just add as many Drupal installations as you want in sub-folders, while they are automatically clean-URL enabled. :)
Drupal 8: Entities and data integration
As follow-up to my previous blog post Drupal 8: Approaching Content and Configuration Management, I'm going to shortly cover how the Entity API could help us with two more of Dries' points: Web services and information integration.
First off, for getting RESTful web services into core, having a unified API to build upon makes lots of sense. That way we make sure we locally have the same uniform interface for CRUD functions available as we expose it to the web. But moreover, the possibility of having remote entities can help us a lot with integrating with remote systems. In a way, we'll get that anyway once we implement pluggable entity storage controllers (and you can even do so already in D7).
But for that really being useful, we need to know the data we want to work with. This is why, I come up with the hook_entity_property_info() in the Entity API module for d7. While for d7 it is built on top of the stuff that is there anyway, I think it should play a much more central role in D8 for various reasons:
- A description of all the data properties of an entity enables modules to deal with any entity regardless of the entity type just based on the available data properties (and their data types). That way, modules can seamlessly continue to work even with entities stemming from remote systems. This is how, the RestWS, SearchAPI and Rules modules already work in d7.
- With pluggable storage backends, I see no point in SQL-centric schema information except we are going to use SQL based storage. By defining the property info, storage backends can work based on that though, i.e. generate the sql backend can generate the schema out of the property information.
- When working with entities, what bothers is the data actually available in the object. To a module, the internal storage format doesn't matter. In a way, the property information defines the "contract" how the entity has to look like. Given that, all APIs should be built based on that, i.e. efq should accept the value to query for exactly the same way it appears in the entity and not in storage-backend dependend way (no one can predict once storage is pluggable). The very same way display formatters and form widgets could just rely on the described data too.