Introducing fluxkraft - web automation simplified with the power of Rules!
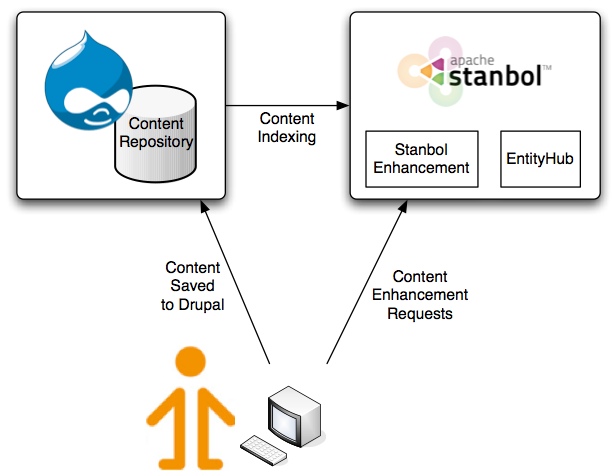
You might have heard some rumors about a tool called "fluxkraft": something like ifttt.com, but with Rules? Or what? Indeed, fluxkraft is one of our latest drunomics lab projects funded by netidee - a Austrian grant for powerful - and open - innovations, and yes - fluxkraft will be a tool for rule-based web automation, built as an open platform on top of Rules and Drupal! So, finally here are some first details on it:
So the idea is to build an easy to use Drupal distribution that allows you to automate various web-based tools like twitter, facebook and dropbox. Yes, you can do that already with services like ifttt.com, but fluxkraft will be an open platform, open-source and free for everyone to use and extend. That way, you can install it on your own servers and keep all the keys to your valuable data secured - and most importantly - under your control!
Then, as it's open source and will come with an API for adding connectors to new services you can simply integrate it with any service you want. So while the tool will provide some essential integrations for services like twitter and facebook from the start, the hope is that community will chime in and provide connectors to a variety of different online services.
Rules?
So how does that tie into Rules? Well, Rules already provides a solid technical base, but we'll add an API for easy-integration with external services to it - so we've got the kraft. But for the flux to gain enough strength, we'll build a new UI that makes it super-simple to create, mix, and share the rules that connect the various services together. So yes - we'll build a new Rules UI! Initially, it will be built separately and power fluxkraft, but if everything works out we'll see a new Rules UI pretty soon!
All fine, Doc? So what's the time(line)? We've mostly finished some initial wireframes, so expect a first shout for feedback on the the new UI at the Rules g.d.o. group soon! Then, the fluxkraft team will be working eagerly on the project such that - maybe - we might have a first preview release out for Drupalcon Portland in May. Howsoever, we'd love to share our learnings and show how we are reloading the Rules UX with fluxkraft, so I've proposed session!
Finally, so who's in the boat? Well, it's me "fago" who will be leading the project during the next months - in fact I'll dedicate most of my time to it. But, fortunately I've got some help of Christian Ziegler aka criz (Strategy, Community Management), Sebastien Siemssen aka fubhy (Development) and Nico Grienauer (Design, Inspirator).
If you are interested, follow @fluxkraft on twitter and provide feedback in a short comment below!
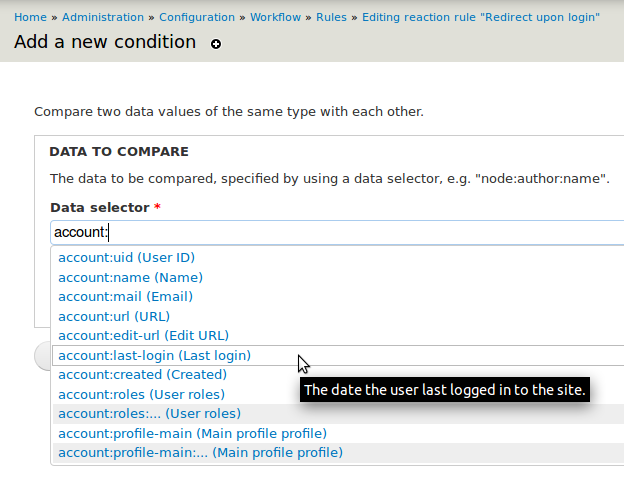 You might note, that data selectors like
You might note, that data selectors like 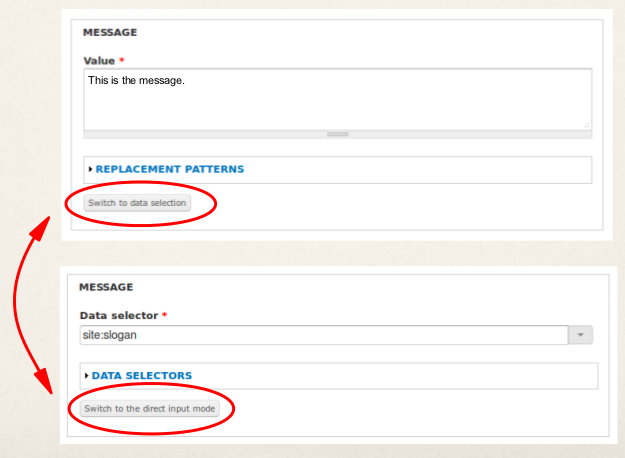
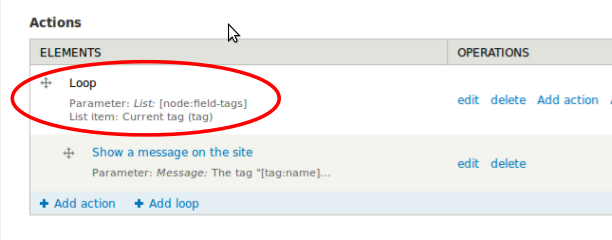 Furthermore, one can access individual list items directly using the data selector - just use
Furthermore, one can access individual list items directly using the data selector - just use 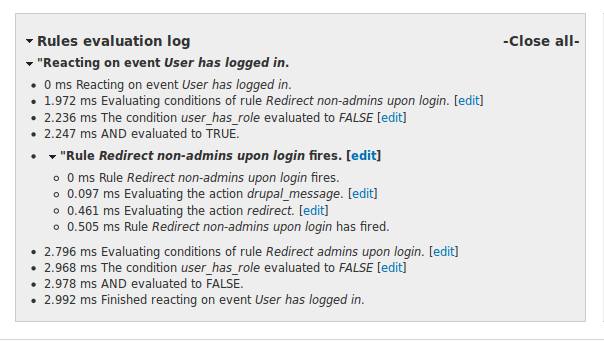
 Unfortunately, the data of the city of Linz required some custom massaging in order to get proper geo coordinates from the project they used. Thus, we were not able to create easy to use feeds configurations for Linz as we've done for Vienna. Maybe the city of Linz improves that in the future...
Unfortunately, the data of the city of Linz required some custom massaging in order to get proper geo coordinates from the project they used. Thus, we were not able to create easy to use feeds configurations for Linz as we've done for Vienna. Maybe the city of Linz improves that in the future...